
Exploring Kotlin’s hidden costs — Part 1
Lambda expressions and companion objects
In 2016, Jake Wharton gave a series of interesting talks about Java’s hidden costs. Around the same period he also started advocating the use of the Kotlin language for Android development but barely mentioned the hidden costs of that language, aside from recommending the use of inline functions. Now that Kotlin is officially supported by Google in Android Studio 3, I thought it would be a good idea to write about that aspect of the language by studying the bytecode it produces.
Kotlin is a modern programming language with a lot more syntactic sugar compared to Java, and as such there is equally more “black magic” going on behind the scenes, some of it having non-negligible costs, especially for Android development targeting older and lower-end devices.
This is not a case against Kotlin: I like the language a lot and it increases productivity, but I also believe a good developer needs to know how language features work internally in order to use them more wisely. Kotlin is powerful and some famous quote says:
“With great power comes great responsibility.”
These articles will focus solely on the JVM/Android implementation of Kotlin 1.1, not the Javascript implementation.
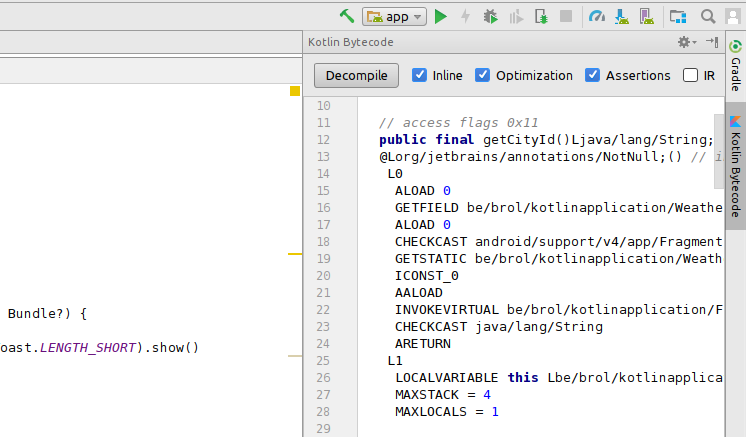
Kotlin Bytecode inspector
This is the tool of choice to figure out how Kotlin code gets translated to bytecode. With the Kotlin plugin installed in Android Studio, select the “Show Kotlin Bytecode” action to open a panel showing the bytecode of the current class. You can then press the “Decompile” button in order to read the equivalent Java code.
In particular, I’ll mention each time a Kotlin feature involves:
- Boxing primitive types, which allocates short-lived objects
- Instantiating extra objects not directly visible in code
- Generating extra methods. As you may know, in Android applications the number of allowed methods inside a single dex file is limited, and going above it requires configuring multidex which comes with limitations and performance penalties, particularly on Android versions before Lollipop.
A note about benchmarks
I deliberately chose not to publish any microbenchmark, because most of them are meaningless, flawed, or both and cannot apply to all code variations and runtime environments. Negative performance impact will usually be amplified when the concerned code is used in loops or nested loops.
Furthermore, execution time is not the only thing to measure: increased memory usage has to be taken into consideration as well, because all allocated memory has to be reclaimed eventually and the cost of garbage collection depends on many factors like the available memory and the GC algorithm being used on the platform.
In a nutshell: if you want to know if a Kotlin construct has some noticeable speed or memory impact, measure your own code on your own target platform.
Higher-order functions and Lambda expressions
Kotlin supports assigning functions to variables and passing them as arguments to other functions. Functions accepting other functions as arguments are called higher-order functions. A Kotlin function can be referenced by its name prefixed with :: or declared directly inside a code block as an anonymous function or using the lambda expression syntax which is the most compact way to describe a function.
Kotlin is one of the best ways to provide lambdas support for Java 6/7 JVMs and Android.
Consider the following utility function which performs arbitrary operations inside a database transaction and returns the number of affected rows:
fun transaction(db: Database, body: (Database) -> Int): Int {
db.beginTransaction()
try {
val result = body(db)
db.setTransactionSuccessful()
return result
} finally {
db.endTransaction()
}
}We can call this function by passing a lambda expression as last argument, using a syntax similar to Groovy:
val deletedRows = transaction(db) {
it.delete("Customers", null, null)
}But Java 6 JVMs don’t support lambda expressions directly. So how are they translated to bytecode? As you might expect, lambdas and anonymous functions are compiled as Function objects.
Function objects
Here is the Java representation of the above lambda expression after compilation.
class MyClass$myMethod$1 implements Function1 {
// $FF: synthetic method
// $FF: bridge method
public Object invoke(Object var1) {
return Integer.valueOf(this.invoke((Database)var1));
}
public final int invoke(@NotNull Database it) {
Intrinsics.checkParameterIsNotNull(it, "it");
return it.delete("Customers", null, null);
}
}In your Android dex file, each lambda expression compiled as a Function will actually add 3 or 4 methods to the total methods count.
The good news is that new instances of these Function objects are only created when necessary. In practice, this means:
- For capturing expressions, a new
Functioninstance will be created every time a lambda is passed as argument then garbage-collected after execution; - For non-capturing expressions (pure functions), a singleton
Functioninstance will be created and reused during the next calls.
Since the caller code of our example uses a non-capturing lambda, it is compiled as a singleton and not an inner class:
this.transaction(db, (Function1)MyClass$myMethod$1.INSTANCE);Avoid calling standard (non-inline) higher-order functions repeatedly if they are invoking capturing lambdas in order to reduce pressure on the garbage collector.
Boxing overhead
Contrary to Java 8 which has about 43 different specialized function interfaces to avoid boxing and unboxing as much as possible, the Function objects compiled by Kotlin only implement fully generic interfaces, effectively using the Object type for any input or output value.
/** A function that takes 1 argument. */
public interface Function1<in P1, out R> : Function<R> {
/** Invokes the function with the specified argument. */
public operator fun invoke(p1: P1): R
}This means that calling a function passed as argument in a higher-order function will actually involve systematic boxing and unboxing when the function involves primitive types (like Int or Long) for input values or the return value. This may have a non-negligible impact on performance, especially on Android.
In our compiled lambda above, you can see that the result is boxed to an Integer object. The caller code will then immediately unbox it.
Be careful when writing a standard (non-inline) higher-order function involving an argument function using primitive types for input or output values. Calling this argument function repeatedly will put more pressure on the garbage collector through boxing and unboxing operations.
Inline functions to the rescue
Thankfully, Kotlin features a wonderful trick to avoid paying any of these costs when using lambda expressions: declaring the higher-order function as inline. This will make the compiler inline the function body directly inside the caller code, avoiding the call entirely. For higher-order functions the benefits are even greater because the body of the lambda expressions passed as arguments will be inlined as well. The practical effects are:
- No
Functionobjects will be instantiated when the lambda is declared; - No boxing or unboxing will be applied to the lambda input and output values targeting primitive types;
- No methods will be added to the total methods count;
- No actual function call will be performed. This can improve performance for CPU-heavy code where the function is used many times.
After declaring our transaction() function as inline, the Java representation of our caller code effectively becomes:
db.beginTransaction();
try {
int result$iv = db.delete("Customers", null, null);
db.setTransactionSuccessful();
} finally {
db.endTransaction();
}This killer feature comes with a few caveats:
- An inline function can not call itself directly or through another inline function;
- A public inline function declared in a class can only access the public functions and fields of that class;
- The code will grow in size. Inlining a long function referenced many times can make the generated code significantly larger, even more if this long function is itself referencing other long inline functions.
When possible, declare higher-order functions as
inline. Keep them short, moving big blocks of code to non-inline functions if required.
You can also inline functions called from performance-critical portions of the code.
We’ll discuss other performance benefits of inline functions in a future article.
Companion objects
Kotlin classes have no static fields or methods. Instead, fields and methods that are not instance-related can be declared in a companion object inside the class.
Accessing private class fields from its companion object
Consider the following example:
class MyClass private constructor() {
private var hello = 0
companion object {
fun newInstance() = MyClass()
}
}When compiled, a companion object is implemented as a singleton class. This means that just like for any Java class whose private fields need to be accessible from other classes, accessing a private field (or constructor) of the outer class from the companion object will generate additional synthetic getter and setter methods. Each read or write access to a class field will result in a static method call in the companion object.
ALOAD 1
INVOKESTATIC be/myapplication/MyClass.access$getHello$p (Lbe/myapplication/MyClass;)I
ISTORE 2In Java we would use the package visibility for these fields to avoid generating these methods. However, there is no package visibility in Kotlin. Using the public or internal visibility instead will result in Kotlin generating default getter and setter instance methods to make the fields accessible to the outside world, and calling instance methods is technically more expensive than calling static methods. So don’t bother changing the visibility of these fields for optimization reasons.
If you need repeated read or write access to a class field from a companion object, you may cache its value in a local variable to avoid repeated hidden method calls.
Accessing constants declared in a companion object
In Kotlin you typically declare “static” constants you use in your class inside a companion object.
class MyClass {
companion object {
private val TAG = "TAG"
}
fun helloWorld() {
println(TAG)
}
}That code looks neat and simple, but what happened behind the scenes until Kotlin 1.2.40 was quite ugly.
Before Kotlin 1.2.40
For the same reasons mentioned above, accessing a private constant declared in the companion object will actually generate an additional synthetic getter method in the companion object implementation class.
GETSTATIC be/myapplication/MyClass.Companion : Lbe/myapplication/MyClass$Companion;
INVOKESTATIC be/myapplication/MyClass$Companion.access$getTAG$p (Lbe/myapplication/MyClass$Companion;)Ljava/lang/String;
ASTORE 1But things get worse. The synthetic method does not actually return the value; it calls an instance method which is a getter generated by Kotlin:
ALOAD 0
INVOKESPECIAL be/myapplication/MyClass$Companion.getTAG ()Ljava/lang/String;
ARETURNWhen the constant is declared public instead of private, this getter method is public and able to be called directly, so the synthetic method of the previous step is not needed. But Kotlin still requires calling a getter method to read a constant.
So, are we done yet? No! It turns out that in order to store the constant value, the Kotlin compiler generates an actual private static final field at the main class level and not inside the companion object. But, because the static field is declared as private in the class, another synthetic method is needed to access it from the companion object.
INVOKESTATIC be/myapplication/MyClass.access$getTAG$cp ()Ljava/lang/String;
ARETURNAnd that synthetic method reads the actual value, at last:
GETSTATIC be/myapplication/MyClass.TAG : Ljava/lang/String;
ARETURNIn other words, when you access a private constant field in a companion object from a Kotlin class before Kotlin 1.2.40, instead of reading a static field directly like Java does, your code will actually:
- call a static method in the companion object,
- which will in turn call an instance method in the companion object,
- which will in turn call a static method in the class,
- which will read the static field and return its value.
Here is the equivalent Java code:
public final class MyClass {
private static final String TAG = "TAG";
public static final Companion companion = new Companion();
// synthetic
public static final String access$getTAG$cp() {
return TAG;
}
public static final class Companion {
private final String getTAG() {
return MyClass.access$getTAG$cp();
}
// synthetic
public static final String access$getTAG$p(Companion c) {
return c.getTAG();
}
}
public final void helloWorld() {
System.out.println(Companion.access$getTAG$p(companion));
}
}So can we get lighter bytecode? Yes, but not in every case.
First, it is possible to completely avoid any method call by declaring the value as a compile-time constant using the const keyword. This will effectively inline the value directly in the calling code, but you can only use this for primitive types and Strings.
class MyClass {
companion object {
private const val TAG = "TAG"
}
fun helloWorld() {
println(TAG)
}
}Second, you can use the @JvmField annotation on a public field in the companion object to instruct the compiler to not generate any getter or setter and expose it as a static field in the class instead, just like pure Java constants. In fact, this annotation has been created solely for Java compatibility reasons and I would definitely not recommend to clutter your beautiful Kotlin code with an obscure interop annotation if you don’t need your constant to be accessible from Java code. Also, it can only be used for public fields. In the context of Android development, you will probably only use this annotation to implement Parcelable objects manually:
class MyClass() : Parcelable {
companion object {
@JvmField
val CREATOR = creator { MyClass(it) }
}
private constructor(parcel: Parcel) : this()
override fun writeToParcel(dest: Parcel, flags: Int) {}
override fun describeContents() = 0
}Finally, you can also use a tool like ProGuard or R8 to optimize the bytecode and let it merge these chained method calls together. This requires optimizations to be enabled.
Before Kotlin 1.2.40, reading a “static” field from a companion object from the main class adds two to three additional levels of indirection in Kotlin compared to Java and two to three additional methods will be generated for each of these fields.
Always declare primitive type and String constants using the const keyword to avoid this.
For other types of constants and mutable fields you can’t, so if you need to access them repeatedly, you may want to cache the value in a local variable.Also, prefer storing public global constants in their own object rather than a companion object.
Since Kotlin 1.2.40

After the original publication of this article, an optimization has been introduced in version 1.2.40 of the Kotlin compiler (released on April 19, 2018), solving the issue of having to go through 3 different method calls for the common case of reading a private field declared in the companion object.
The values declared in the companion object are still stored in the form of static fields in the main class (not in the companion object class), but now they will be accessed directly from the main class without any indirection!
The equivalent Java code would now be:
public final class MyClass {
private static final String TAG = "TAG";
public static final Companion companion = new Companion();
public static final class Companion {
}
public final void helloWorld() {
System.out.println(TAG);
}
}Since Kotlin 1.2.40, there is no hidden cost compared to Java when accessing a field declared in a companion object from the main class, besides the creation of the companion object class itself. If the companion object doesn’t contain any method like in the above example, its class will be removed by a code shrinker like Proguard or R8.
Methods declared in the companion object, on the other hand, are the ones paying a small cost: they still need to go through a single synthetic accessor method to be able to access private fields declared in the companion object, since these fields are actually stored in the main class.
That’s all for this first article. Hopefully this gave you a better understanding of the implications of using these Kotlin features. Keep this in mind in order to write smarter code without sacrificing readability nor performance.
Keep reading by heading to part 2: local functions, null safety and varargs.
